

Data warehouse tech stack
Data warehouse tech stack with PostgreSQL, DBT, Airflow and Redash
The objective of this initiative is to support the city traffic department by employing swarm UAVs (drones) to gather comprehensive traffic data from various city locations. The collected data will be utilized to enhance traffic flow within the city and contribute to undisclosed projects. To facilitate this, we aim to construct a scalable data warehouse capable of hosting vehicle trajectory data derived from the analysis of footage captured by swarm drones and static roadside cameras. The design of the data warehouse accommodates future requirements and effectively organize the data to enable efficient querying for various downstream projects. The chosen framework for this endeavor is the Extract Load Transform (ELT) approach, leveraging the capabilities of DBT.
What is EDA?
ELT (Extract, Load, Transform) is a data processing framework used in analytics. It involves extracting raw data, loading it into a data warehouse, and performing transformations within the storage system. Unlike traditional ETL, ELT leverages the capabilities of modern data warehousing solutions for more scalable and flexible processing.
Dataset Description
The pNEUMA dataset offers naturalistic trajectories of around half a million vehicles, collected by a unique experiment using a swarm of drones in Athens, Greece’s congested downtown area. Each file, representing a specific (area, date, time) combination, is approximately 87MB in size. The trajectories are extracted from video frames recorded during the experiment. Resources like “tud-hri/travia” and “JoachimLandtmeters/pNEUMA_mastersproject” on GitHub provide tools for visualization and analysis, facilitating exploration of this rich dataset. Access and download the dataset from https://zenodo.org/records/7426506.
Data Preparation
In the data preparation phase, our Python script acts as a data maestro, leveraging Pandas and NumPy to effortlessly load and explore datasets. Using Pandas’ read_csv function with custom separators, we swiftly ingest the CSV file into a Pandas DataFrame. This sets the foundation for a deep dive into our data, where Python’s versatile toolkit enables seamless cleaning, transformation, and organization.
Tech stack used
Apache Airflow:
Purpose: Workflow automation and scheduling.
Key Features: DAGs (Directed Acyclic Graphs) for defining workflows, scheduling and orchestrating tasks, monitoring and logging.
Use Case: Automating and orchestrating data loading to database, and scheduled dbt tasks.
dbt (data build tool):
Purpose: Transforming and modeling data in the data warehouse.
Key Features: SQL-based transformations, version control for analytics code, modularization of SQL queries.
Use Case: Transforming raw data into structured, analytics-ready datasets within a data warehouse.
PostgreSQL (Postgres):
Purpose: Relational database management system (RDBMS).
Key Features: ACID compliance, extensibility, support for JSON data types.
Use Case: Storing and managing structured data, commonly used as a data warehouse backend.
Redash:
Purpose: Business intelligence (BI) and visualization tool.
Key Features: Querying multiple data sources, creating dashboards and visualizations, sharing and collaborating on data insights.
Use Case: Creating and sharing visualizations and dashboards for data analysis and reporting.
How They Work Together:
Apache Airflow orchestrates and schedules data workflows, including dbt transformations.
dbt transforms and models data in the PostgreSQL data warehouse.
Redash connects to PostgreSQL to visualize and explore transformed data.
Methodology
Creating Virtual Machine
To initiate the project, the first step involved establishing a dedicated virtual machine, a fundamental element for achieving a production-ready setup with comprehensive Dockerization. Utilizing the robust Proxmox virtualization platform in the home lab, a virtual machine was configured with substantial resources: 4 CPU sockets, 5GB of RAM, and a capacious 64GB hard disk. This strategic allocation ensures optimal performance and scalability, creating a foundation for a seamless Dockerized environment. Following the virtual machine setup, Debian 12 (Bookworm) was installed as the operating system, laying a sturdy groundwork for subsequent development and deployment phases in this exciting project.
Promox VM running debian12
Installing and using Airflow
Having configured the dedicated virtual machine, the next steps involved optimizing containerization through the installation of Docker. Following this, Apache Airflow was employed to efficiently manage data loading using Directed Acyclic Graphs (DAGs). To enhance the structure of data processing, I developed modules dedicated to extraction, logging, and parsing. Progressing further, a pivotal step was the creation of a loader DAG within Airflow, crucial for orchestrating the data workflow. The Airflow setup encompassed the crafting of a docker-compose.yml file, ensuring the installation of essential packages and proper volume mounting for seamless functionality.
Portainer container management
The loading process was scheduled to occur daily at midnight using the DAG file. Subsequently, the dbt transformation was seamlessly scheduled to follow suit. The data was stored in two distinct tables, each containing the relevant information. The orchestration of automatic data transformation through dbt was scheduled using a bash script. This meticulous scheduling ensures a timely and automated workflow, maintaining data integrity and facilitating efficient transformations for the project.

Airflow dashboard to manage dags
Stages within Airflow
Daily Loading Schedule with DAG
The data loading process is scheduled daily at midnight using a Directed Acyclic Graph (DAG) file in Apache Airflow. This systematic scheduling ensures a consistent and timely influx of data.
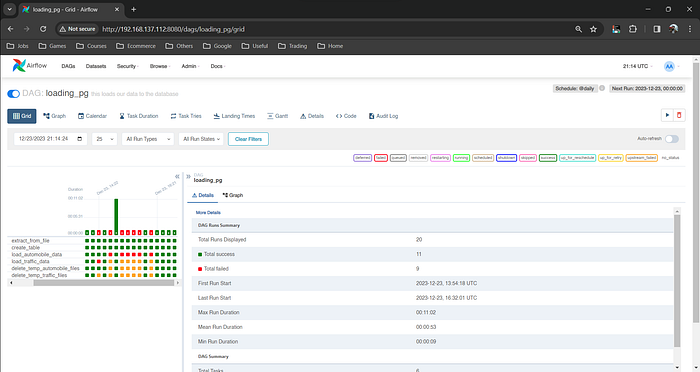
Loading data using the loading DAG created

Graph of the loading DAG
Seamless dbt Transformation Schedule
Following the loading process, the dbt transformation is scheduled seamlessly. This step ensures structured data transformation after the loading phase, maintaining a logical flow in the overall data pipeline.
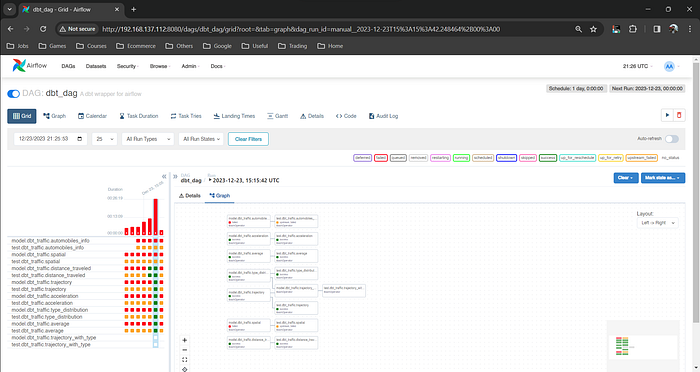
dbt automation DAG

dbt automation DAG
Using Dbt To Create Transformative Models and Lineage
Leveraging dbt, a model was crafted to transform data, resulting in tailored tables and views for detailed analysis. Utilizing dbt’s features, a key aspect involved establishing lineage between datasets, enabling the creation of a relationship-based view. This enhanced understanding and analysis. The interconnected views and tables, orchestrated via dbt, streamlined transformation and offered a comprehensive perspective, empowering robust analytics.
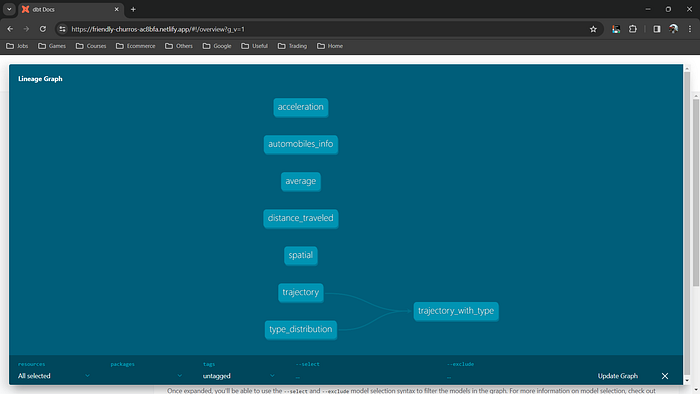
lineage graph to showcase tranform models relationships
To access the deployed documentation for dbt and explore the insights derived from our meticulously crafted models, please visit [dbt documentation]. Dive into the comprehensive lineage views, detailed tables, and refined analysis that empower our data analytics.
Empowering Data Insights with Redash
After successfully loading and transforming the data, we seamlessly integrated Redash into our workflow by deploying the Dockerized version. Connecting Redash to our PostgreSQL database, where the data loading and transformation occurred, was a straightforward process. This integration allows us to leverage Redash’s powerful visualization and querying capabilities, providing a user-friendly interface to interact with and derive insights from the transformed data.
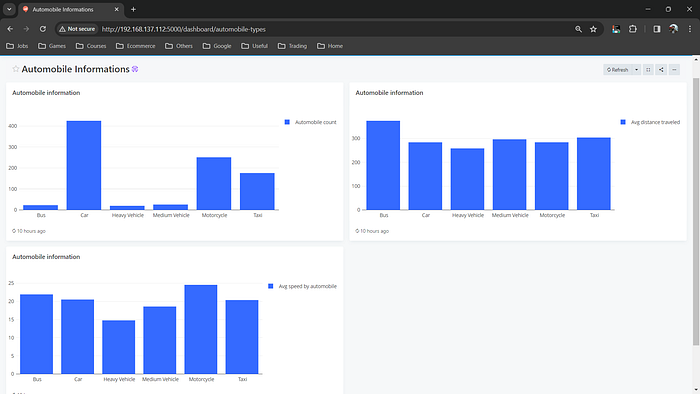
Showing automobile informations
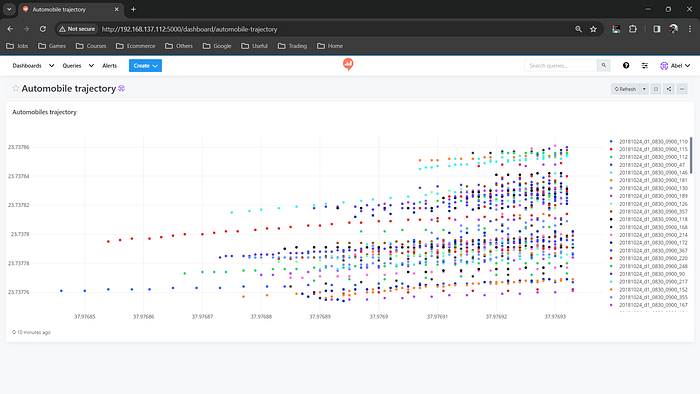
Showing automobile path along a path
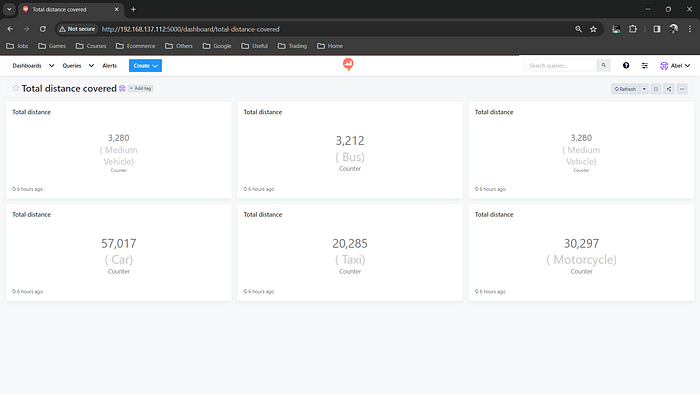
Total distance covered by different types of automo
Limitations and future work
Limitations
Scalability Concerns: While the current setup is designed to handle the scale of the pNEUMA dataset, future expansion may pose scalability challenges. Considerations for horizontal scaling and optimizing resource utilization may be necessary for larger datasets or increased traffic data collection.
Real-time Processing: The current architecture focuses on batch processing with daily data loading and transformations. Real-time data processing for immediate insights could be a valuable addition, especially for time-sensitive traffic management scenarios.
Future work
Predictive Analytics: Enhance the capabilities of the data warehouse by incorporating predictive analytics models. This could involve forecasting traffic patterns, identifying potential congestion areas, and proactively optimizing traffic flow based on historical data.
Integration of Additional Data Sources: Extend the data collection scope by integrating additional data sources, such as weather data, events, or public transportation schedules. This broader dataset could provide a more holistic understanding of factors influencing traffic dynamics.
Conclusion
Our initiative harnesses the potential of PostgreSQL, dbt, Apache Airflow, and Redash to construct a scalable data warehouse for urban traffic management. Focused on enhancing traffic flow and supporting the city traffic department’s objectives, our ELT framework, driven by dbt, ensures efficient data transformations and sets the stage for future needs.
From seamless data preparation using Python to orchestrating workflows with Apache Airflow and transforming data with dbt, our tech stack operates harmoniously. The integration of Redash provides an intuitive interface for visualizing and querying transformed data, enriching the analytics experience.
Our staged methodology, from virtual machine setup to daily loading schedules and dbt transformations, signifies a commitment to a robust data pipeline. While acknowledging limitations, future endeavors include predictive analytics, additional data source integration, and advanced visualization.
In conclusion, our data warehouse initiative represents a transformative approach to urban data analytics, showcasing the potential to shape smarter cities through collaboration, innovation, and continuous improvement.
Newsletter
If you liked this post, sign up to get updates in your email when I write something new! No spam ever.
Subscribe to the Newsletter